2020. 10. 16. 00:54ㆍ컴퓨터 수업/자료구조
원래 Linked-list가 더 어울리는 말이지만, 내가 공부한 바로는 Linked-Node라고 명명하는것이 현 내 상황에서는 더 어울리는 것 같다.
먼저 Array-based 와 Linked 의 비용적인 문제를 살펴보자면 (여기서도 Array-based와 Linked-list라고 표현하지 않고 Linked라고 표현했다.)


보다시피 Linked-Data-structure는 자료형이 늘어날때마다 Byte가 증가하는 것을 관찰 할 수 있다.
따라서, ItemType의 크기가 작을수록 Array-based를 지향하고, ItemType의 크기가 클 수록
Linked-based를 지향하는것이 좋다.
Node란 무엇인가? ★
Node란 데이터 필드로 value와 next라는 포인터변수를 가진 객체이다.
이 노드라는 것에 대해 이해하려면 3가지 값에 초점을 둬야한다.
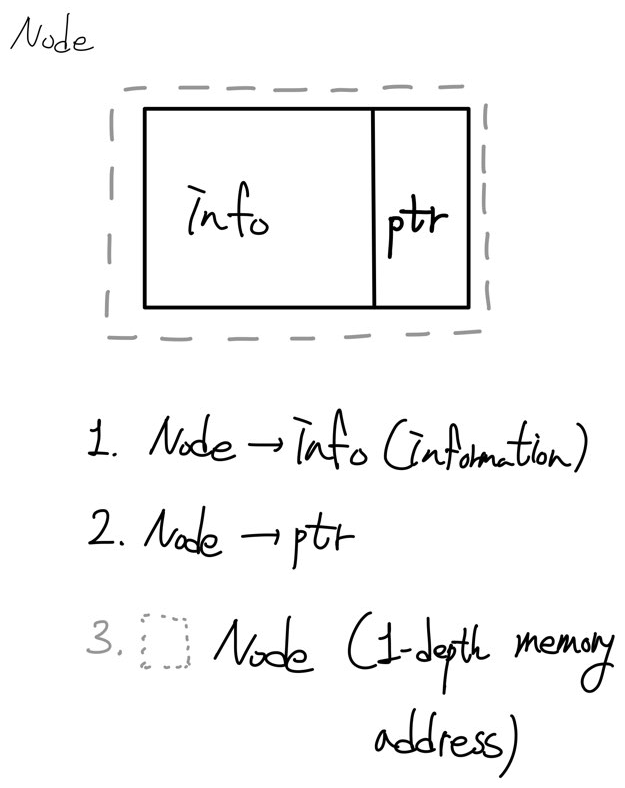
1. 노드의 값 (information)이다.
Node는 class로 NodeType<ItemType> * node라고 선언할것이니,
접근은 -> operator로 수행해야한다.
2. 노드의 ptr라는 변수이다. 이는 절대 node의 memory가 아니라 그저 다음 node가 어디인지를
저장하는 포인터변수이다.
3. 이것이 node의 메모리주소이다. node는 포인터변수로 선언되었으니 node는 1-depth meomory address이다.
가장 쉬운 자료구조가 stack이니 linked-stack을 구현하려고 해보자.
@ 먼저 NodeType에 대한 선언이 필요할 것이다.
template <class ItemType>
class NodeType
{
public:
ItemType info;
NodeType *next;
};이는 NodeType.h에 구현해두었다.
-info와 next를 public 접근지정자로 선언해두었다.
따라서 struct로 구현할 까 하다가 (struct는 모든 멤버가 public이다.) 그냥 수업과 다르게 이렇게 구현해보았다.
-next의 자료형(data-type)을 NodeType으로 선언해두었다.
언제나 포인터의 자료형을 무엇으로 해야할지 헷갈리곤 하는데, 명확하다.
해당 포인터가 어떤 자료형을 가르킬것인지에 따라 다르다.
이때 next는 다음 Node의 memory address를 가르킬 것이기 때문에, NodeType으로 선언했다.
@StackType을 구현할 것이다.
먼저 생각해 볼 것이, Constructor, Observer, Transformer, iterator로 나누어 어떤 메소드들이 존재하는지 고려해보아야한다.
먼저 Constructor에는 Constructor , Destructor가 존재할것이고
Observer에는 Top, IsEmpty, IsFull이 존재할 것이다.
Transformer에는 Push, Pop이 존재할것이다.
그에 대한 interface를 다음과 같이 구현해두었다.
template <class ItemType>
class StackType
{
public:
//Constructor
StackType();
~StackType();
//Observer
bool isFull();
bool isEmpty();
ItemType Top();
//Transformer
void Pop();
void Push(const ItemType& item);
private:
NodeType<ItemType> * topPtr;
};-topPtr을 NodeType class에서와 다르게 NodeType<ItemType> 자료형으로 선언했다.
NodeType class에서 next라는 포인터변수를 선언할때 NodeType * next;로 선언해도 컴파일 에러가
발생하지 않았다. 이는 NodeType의 template변수가 정의되면 명시적으로 NodeType *next의 ItemType이 결정되기 때문이다.
하지만 위의 StackType의 경우에는 NodeType<ItemType> * topPtr이라고 선언하지 않고, NodeType *topPtr이라고 선언한다면 topPtr의 템플릿 변수가 무엇인지 명시적이지 못하므로 컴파일 에러가 난다.
--정리하자면
NodeType에서와 같이 회귀적으로 class 내부에서 선언한다면 <ItemType>과 같은 템플릿 변수를 명시하지 않아도된다. 하지만,
StackType과 같이 다른 class에서 NodeType이라는 자료형을 call한다면 템플릿변수를 명시해야한다.
-이를 어떻게 구현하냐는 이제 logical한 level이다. 이를 사용하는것은 application level이고.
따라서 이에대한 구현을 logical한 level에서 시도해보겠다. 구현을 하면서 물론 추가적인 멤버가 발생할 수 있다.
@Implement
<Constructor>
//Constructor
template <class ItemType>
StackType<ItemType>::StackType(){
topPtr = nullptr;
};-scope에는 <ItemType>을 썼지만 StackType()이란 생성자 메소드에는 작성하지 않았다.
이를 보면 ItemType의 형태에 따라, 메소드 오버로딩이 가능함을 예상할 수 있다.
-topPtr 을 nullptr로 지정해뒀다.
근본적으로 stack은 node가 아무것도 없다면 topPtr이 아무것도 가르키지 않도록 해야한다.
<Destructor>
//Destructor
template <class ItemType>
StackType<ItemType>::~StackType()
{
NodeType<ItemType> *temp = nullptr;
while(topPtr != nullptr) // when while-loop is ended, topPtr = nullptr
{
temp = topPtr;
topPtr = topPtr->next;
delete temp;
}
}-topPtr을 하나씩 밀면서 모든 Node 메모리를 해제해주는 행위이다.
끝까지 탐색하는 logic에 topPtr!=nullptr을 사용했음을 주의하게 보자.
이 로직은 앞으로도 자주 이용 할 것이다.
-첫 시행시 temp에 topPtr이 담기고, topPtr은 도망가고, temp를 delete하면 temp라는 포인터 변수는 어떻게 되는거지?
이는 아래 코드 출력 결과를 보면 이해할 수 있다.
#include <iostream>
int main()
{
int* px = new int;
std::cout << px << std::endl;
int* py = new int;
delete px;
std::cout << px << std::endl;
px = py;
std::cout << "px :" << px << std::endl;
std::cout << "py :" << py << std::endl;
}
1.int *px = new int;를 통해 heap memory에 4byte의 메모리를 만들어내고, px가 그쪽의 memory 정보를 갖도록 하였다.
2.py도 마찬가지이다.
3. px를 delete하였으므로 heap memory의 4byte는 사라졌을것이다.
그런데 아직 px가 가르키는 부분이 있다.
4. 이부분을 역참조하여 값을 넣어봤지만 입력되지 않고 런타임에러가 발생하였다.
따라서 이 부분은 레지스터 중 User가 접근할 수 없는 임시메모리 주소라고 사료된다.
5.그렇다고 해서 이 px를 더이상 사용하지 못하는것은 아니다, 이 px에 py의 메모리주소를 할당해주었더니
다시 역참조할 수 있도록 되었다.
결론적으로, delete라는 행위는 해당 포인터변수가 가르키는 메모리의 heap 메모리를 삭제하고, 그 포인터를 잠깐 임시적으로 역참조하지 못하는 공간을 가르키도록 임시처리 해둔다.
따라서 다시 temp라는 포인터변수를 계속 재사용할 수 있다, 포인터변수를 없앤다거나 하는것이 아니다.
<isFull>
template <class ItemType>
bool StackType<ItemType>::isFull() {
try {
auto *temp = new NodeType<ItemType>;
delete temp;
return false;
} catch (std::bad_alloc &bad_alloc) {
return true;
}
}-조금은 brutal한 방법이지만, new라는 연산자를 이용해서 heap memory에 할당을 하고
만약 memory 생성이 실패했다면 true를 반환하여 isFull을 알아본다
여기서 알 수 있는것은 new라는 연산자에는 throw std::bad_alloc이 있다는것을 알 수 있다.
<isEmpty>
template <class ItemType>
bool StackType<ItemType>::isEmpty() {
return (topPtr == nullptr);
}- 원래 if / else를 이용하려 했으나 이런식으로 bool return 함수에는 사용할 수 있다는것을 기억해두자
if / else를 최대한 줄여야 한다.
<Top>
template <class ItemType>
ItemType StackType<ItemType>::Top() {
if(isEmpty()) {
throw std::exception();
}else{
return topPtr->info;
}
}Stack이 비었을때의 예외처리, 그리고 return topPtr->info로 구성했다.
<Pop>

template <class ItemType>
void StackType<ItemType>::pop(){
if(isEmpty()){
throw std::exception();
}else{
NodeType<ItemType>* temp;
temp = topPtr;
topPtr = topPtr->next;
delete temp;
}
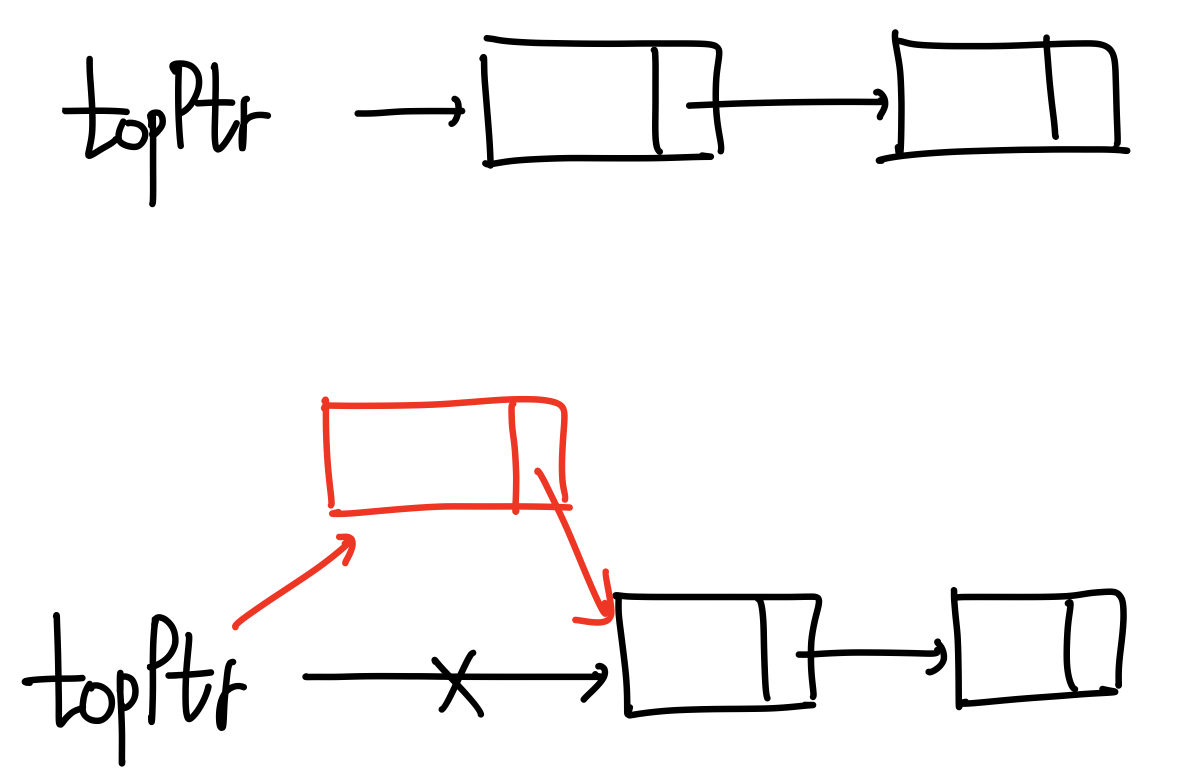
}-topPtr의 다음 화살표를 끊어내고 빨간화살표를 잇는 작업은
topPtr = topPtr->next;로 행한다
-없애려 하던 Node의 화살표 (next) 변수는 delete와 함께 사라질것이기 때문에 고민하지 않아도된다.
이 부분이 어떻게 heap에서 포인터변수가 사라지는지를 일반변수와 비교하여 고민 해 볼 것.
<Push>
template <class ItemType> void StackType<ItemType>::push(const ItemType &item) {
if (isFull()) {
throw std::exception();
} else {
NodeType<ItemType> *newNode = new NodeType<ItemType>;
newNode->info = item;
newNode->next = topPtr;
topPtr = newNode;
}
}
'컴퓨터 수업 > 자료구조' 카테고리의 다른 글
| 자료구조_중간고사_준비 (0) | 2020.10.20 |
|---|---|
| 큐 Queue (0) | 2020.10.07 |
| 리스트와 스택의 차이 (0) | 2020.10.05 |
| Big O notation (0) | 2020.09.15 |
| List (0) | 2020.09.15 |